@ -0,0 +1,6 @@
|
||||
__pycache__
|
||||
*.pt
|
||||
*.txt
|
||||
*.png
|
||||
events.*
|
||||
outputs
|
||||
@ -0,0 +1,98 @@
|
||||
# AOT-GAN for High-Resolution Image Inpainting
|
||||
|
||||
### [Arxiv Paper](https://github.com/researchmm/AOT-GAN-for-Inpainting) |
|
||||
|
||||
AOT-GAN: Aggregated Contextual Transformations for High-Resolution Image Inpainting<br>
|
||||
[Yanhong Zeng](https://sites.google.com/view/1900zyh), [Jianlong Fu](https://jianlong-fu.github.io/), [Hongyang Chao](https://scholar.google.com/citations?user=qnbpG6gAAAAJ&hl), and [Baining Guo](https://www.microsoft.com/en-us/research/people/bainguo/).<br>
|
||||
|
||||
|
||||
<!-- ------------------------------------------------ -->
|
||||
## Citation
|
||||
If any part of our paper and code is helpful to your work, please generously cite with:
|
||||
```
|
||||
@inproceedings{yan2021agg,
|
||||
author = {Zeng, Yanhong and Fu, Jianlong and Chao, Hongyang and Guo, Baining},
|
||||
title = {Aggregated Contextual Transformations for High-Resolution Image Inpainting},
|
||||
booktitle = {Arxiv},
|
||||
pages={-},
|
||||
year = {2020}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
<!-- ---------------------------------------------------- -->
|
||||
## Introduction
|
||||
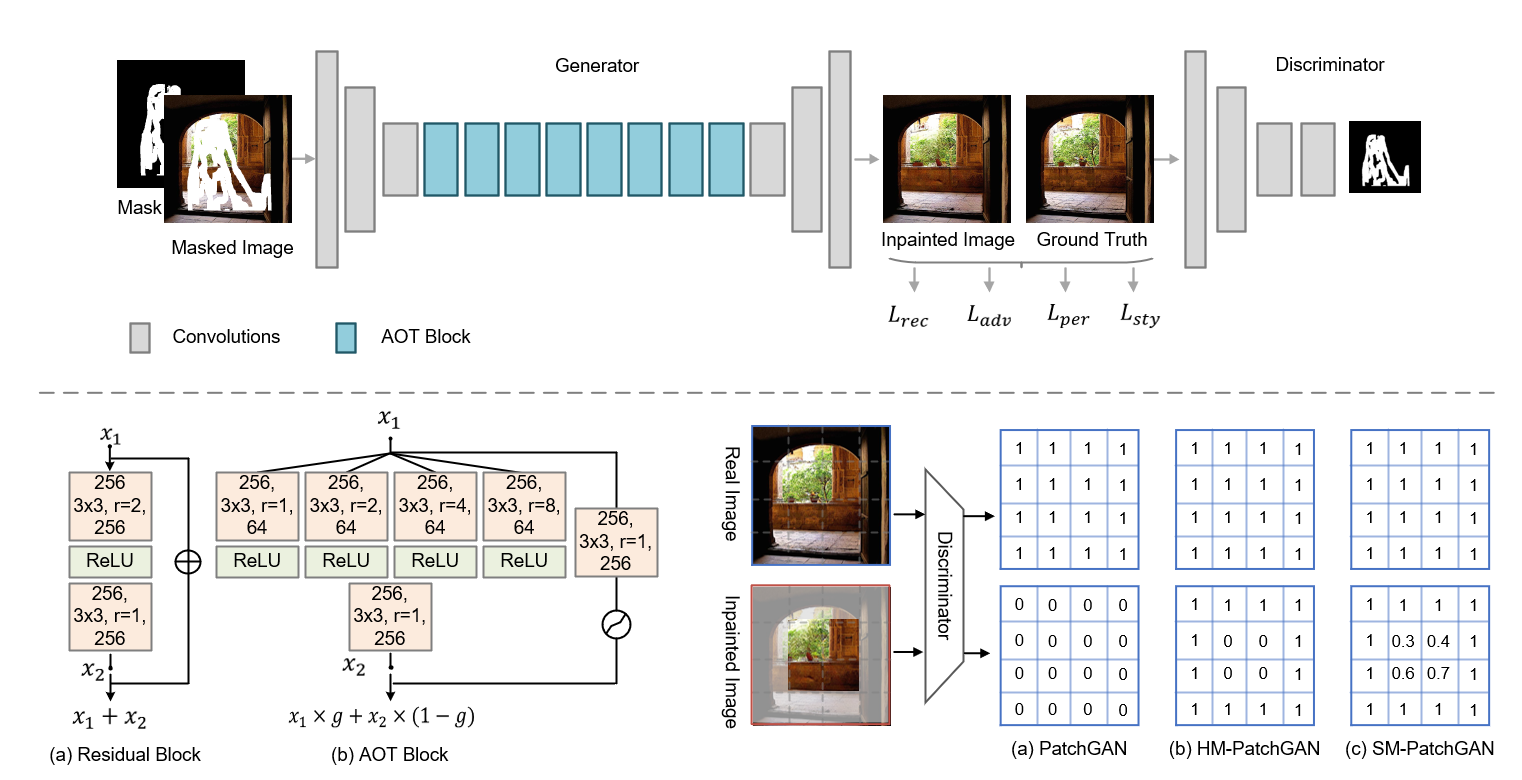
Despite some promising results, it remains challenging for existing image inpainting approaches to fill in large missing regions in high resolution images (e.g., 512x512). We analyze that the difficulties mainly drive from simultaneously inferring missing contents and synthesizing fine-grained textures for a extremely large missing region.
|
||||
We propose a GAN-based model that improves performance by,
|
||||
1) **Enhancing context reasoning by AOT Block in the generator.** The AOT blocks aggregate contextual transformations with different receptive fields, allowing to capture both informative distant contexts and rich patterns of interest for context reasoning.
|
||||
2) **Enhancing texture synthesis by SoftGAN in the discriminator.** We improve the training of the discriminator by a tailored mask-prediction task. The enhanced discriminator is optimized to distinguish the detailed appearance of real and synthesized patches, which can in turn facilitate the generator to synthesize more realistic textures.
|
||||
|
||||
|
||||
<!-- ------------------------------------------------ -->
|
||||
## Results
|
||||

|
||||

|
||||
|
||||
|
||||
<!-- -------------------------------- -->
|
||||
## Prerequisites
|
||||
* python 3.8.8
|
||||
* [pytorch](https://pytorch.org/) (tested on Release 1.8.1)
|
||||
|
||||
<!-- --------------------------------- -->
|
||||
## Installation
|
||||
|
||||
Clone this repo.
|
||||
|
||||
```
|
||||
git clone git@github.com:researchmm/AOT-GAN-for-Inpainting.git
|
||||
cd AOT-GAN-for-Inpainting/
|
||||
```
|
||||
|
||||
For the full set of required Python packages, we suggest create a Conda environment from the provided YAML, e.g.
|
||||
|
||||
```
|
||||
conda env create -f environment.yml
|
||||
conda activate inpainting
|
||||
```
|
||||
|
||||
<!-- --------------------------------- -->
|
||||
## Datasets
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- -------------------------------------------------------- -->
|
||||
## Getting Started
|
||||
|
||||
1. Training:
|
||||
* Prepare training images filelist [[our split]](https://drive.google.com/open?id=1_j51UEiZluWz07qTGtJ7Pbfeyp1-aZBg)
|
||||
* Modify [celebahq.json](configs/celebahq.json) to set path to data, iterations, and other parameters.
|
||||
* Our codes are built upon distributed training with Pytorch.
|
||||
* Run `python train.py -c [config_file] -n [model_name] -m [mask_type] -s [image_size] `.
|
||||
* For example, `python train.py -c configs/celebahq.json -n pennet -m pconv -s 512 `
|
||||
2. Resume training:
|
||||
* Run `python train.py -n pennet -m pconv -s 512 `.
|
||||
3. Testing:
|
||||
* Run `python test.py -c [config_file] -n [model_name] -m [mask_type] -s [image_size] `.
|
||||
* For example, `python test.py -c configs/celebahq.json -n pennet -m pconv -s 512 `
|
||||
4. Evaluating:
|
||||
* Run `python eval.py -r [result_path]`
|
||||
|
||||
<!-- ------------------------------------------------------------------- -->
|
||||
## Pretrained models
|
||||
[CELEBA-HQ](https://drive.google.com/open?id=1d7JsTXxrF9vn-2abB63FQtnPJw6FpLm8) |
|
||||
[Places2](https://drive.google.com/open?id=19u5qfnp42o7ojSMeJhjnqbenTKx3i2TP)
|
||||
|
||||
Download the model dirs and put it under `experiments/`
|
||||
|
||||
|
||||
<!-- ------------------------ -->
|
||||
## TensorBoard
|
||||
Visualization on TensorBoard for training is supported.
|
||||
|
||||
Run `tensorboard --logdir [log_fold] --bind_all` and open browser to view training progress.
|
||||
|
||||
|
||||
### License
|
||||
Licensed under an MIT license.
|
||||
{kind=link}
|
After Width: | Height: | Size: 246 KiB |
{kind=link}
|
After Width: | Height: | Size: 10 MiB |
{kind=link}
|
After Width: | Height: | Size: 635 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.7 MiB |
{kind=link}
|
After Width: | Height: | Size: 12 MiB |
{kind=link}
|
After Width: | Height: | Size: 243 KiB |
{kind=link}
|
After Width: | Height: | Size: 3.7 KiB |
{kind=link}
|
After Width: | Height: | Size: 448 KiB |
{kind=link}
|
After Width: | Height: | Size: 282 KiB |
{kind=link}
|
After Width: | Height: | Size: 266 KiB |
{kind=link}
|
After Width: | Height: | Size: 43 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.6 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.4 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.6 KiB |
{kind=link}
|
After Width: | Height: | Size: 2.2 KiB |
{kind=link}
|
After Width: | Height: | Size: 170 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.7 KiB |
@ -0,0 +1,18 @@
|
||||
from .dataset import InpaintingData
|
||||
|
||||
from torch.utils.data import DataLoader
|
||||
|
||||
|
||||
def sample_data(loader):
|
||||
while True:
|
||||
for batch in loader:
|
||||
yield batch
|
||||
|
||||
|
||||
def create_loader(args):
|
||||
dataset = InpaintingData(args)
|
||||
data_loader = DataLoader(
|
||||
dataset, batch_size=args.batch_size//args.world_size,
|
||||
shuffle=True, num_workers=args.num_workers, pin_memory=True)
|
||||
|
||||
return sample_data(data_loader)
|
||||
@ -0,0 +1,28 @@
|
||||
|
||||
import zipfile
|
||||
|
||||
|
||||
class ZipReader(object):
|
||||
file_dict = dict()
|
||||
|
||||
def __init__(self):
|
||||
super(ZipReader, self).__init__()
|
||||
|
||||
@staticmethod
|
||||
def build_file_dict(path):
|
||||
file_dict = ZipReader.file_dict
|
||||
if path in file_dict:
|
||||
return file_dict[path]
|
||||
else:
|
||||
file_handle = zipfile.ZipFile(path, mode='r', allowZip64=True)
|
||||
file_dict[path] = file_handle
|
||||
return file_dict[path]
|
||||
|
||||
@staticmethod
|
||||
def imread(path, image_name):
|
||||
zfile = ZipReader.build_file_dict(path)
|
||||
data = zfile.read(image_name)
|
||||
im = Image.open(io.BytesIO(data))
|
||||
return im
|
||||
|
||||
|
||||
@ -0,0 +1,80 @@
|
||||
import os
|
||||
import math
|
||||
import numpy as np
|
||||
from glob import glob
|
||||
|
||||
from random import shuffle
|
||||
from PIL import Image, ImageFilter
|
||||
|
||||
import torch
|
||||
import torchvision.transforms.functional as F
|
||||
import torchvision.transforms as transforms
|
||||
from torch.utils.data import Dataset, DataLoader
|
||||
|
||||
class InpaintingData(Dataset):
|
||||
def __init__(self, args):
|
||||
super(Dataset, self).__init__()
|
||||
self.w = self.h = args.image_size
|
||||
self.mask_type = args.mask_type
|
||||
|
||||
# image and mask
|
||||
self.image_path = []
|
||||
for ext in ['*.jpg', '*.png']:
|
||||
self.image_path.extend(glob(os.path.join(args.dir_image, args.data_train, ext)))
|
||||
self.mask_path = glob(os.path.join(args.dir_mask, args.mask_type, '*.png'))
|
||||
|
||||
# augmentation
|
||||
self.img_trans = transforms.Compose([
|
||||
transforms.RandomResizedCrop(args.image_size),
|
||||
transforms.RandomHorizontalFlip(),
|
||||
transforms.ColorJitter(0.05, 0.05, 0.05, 0.05),
|
||||
transforms.ToTensor()])
|
||||
self.mask_trans = transforms.Compose([
|
||||
transforms.Resize(args.image_size, interpolation=transforms.InterpolationMode.NEAREST),
|
||||
transforms.RandomHorizontalFlip(),
|
||||
transforms.RandomRotation(
|
||||
(0, 45), interpolation=transforms.InterpolationMode.NEAREST),
|
||||
])
|
||||
|
||||
|
||||
def __len__(self):
|
||||
return len(self.image_path)
|
||||
|
||||
def __getitem__(self, index):
|
||||
# load image
|
||||
image = Image.open(self.image_path[index]).convert('RGB')
|
||||
filename = os.path.basename(self.image_path[index])
|
||||
|
||||
if self.mask_type == 'pconv':
|
||||
index = np.random.randint(0, len(self.mask_path))
|
||||
mask = Image.open(self.mask_path[index])
|
||||
mask = mask.convert('L')
|
||||
else:
|
||||
mask = np.zeros((self.h, self.w)).astype(np.uint8)
|
||||
mask[self.h//4:self.h//4*3, self.w//4:self.w//4*3] = 1
|
||||
mask = Image.fromarray(m).convert('L')
|
||||
|
||||
# augment
|
||||
image = self.img_trans(image) * 2. - 1.
|
||||
mask = F.to_tensor(self.mask_trans(mask))
|
||||
|
||||
return image, mask, filename
|
||||
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
from attrdict import AttrDict
|
||||
args = {
|
||||
'dir_image': '../../../dataset',
|
||||
'data_train': 'places2',
|
||||
'dir_mask': '../../../dataset',
|
||||
'mask_type': 'pconv',
|
||||
'image_size': 512
|
||||
}
|
||||
args = AttrDict(args)
|
||||
|
||||
data = InpaintingData(args)
|
||||
print(len(data), len(data.mask_path))
|
||||
img, mask, filename = data[0]
|
||||
print(img.size(), mask.size(), filename)
|
||||
@ -0,0 +1,112 @@
|
||||
import cv2
|
||||
import os
|
||||
import importlib
|
||||
import numpy as np
|
||||
from glob import glob
|
||||
|
||||
import torch
|
||||
from torchvision.transforms import ToTensor
|
||||
|
||||
from utils.option import args
|
||||
from utils.painter import Sketcher
|
||||
|
||||
|
||||
|
||||
def postprocess(image):
|
||||
image = torch.clamp(image, -1., 1.)
|
||||
image = (image + 1) / 2.0 * 255.0
|
||||
image = image.permute(1, 2, 0)
|
||||
image = image.cpu().numpy().astype(np.uint8)
|
||||
return image
|
||||
|
||||
|
||||
|
||||
def demo(args):
|
||||
# load images
|
||||
img_list = []
|
||||
for ext in ['*.jpg', '*.png']:
|
||||
img_list.extend(glob(os.path.join(args.dir_image, ext)))
|
||||
img_list.sort()
|
||||
|
||||
# Model and version
|
||||
net = importlib.import_module('model.'+args.model)
|
||||
model = net.InpaintGenerator(args)
|
||||
model.load_state_dict(torch.load(args.pre_train, map_location='cpu'))
|
||||
model.eval()
|
||||
|
||||
for fn in img_list:
|
||||
filename = os.path.basename(fn).split('.')[0]
|
||||
orig_img = cv2.resize(cv2.imread(fn, cv2.IMREAD_COLOR), (512, 512))
|
||||
img_tensor = (ToTensor()(orig_img) * 2.0 - 1.0).unsqueeze(0)
|
||||
h, w, c = orig_img.shape
|
||||
mask = np.zeros([h, w, 1], np.uint8)
|
||||
image_copy = orig_img.copy()
|
||||
sketch = Sketcher(
|
||||
'input', [image_copy, mask], lambda: ((255, 255, 255), (255, 255, 255)), args.thick, args.painter)
|
||||
|
||||
while True:
|
||||
ch = cv2.waitKey()
|
||||
if ch == 27:
|
||||
print("quit!")
|
||||
break
|
||||
|
||||
# inpaint by deep model
|
||||
elif ch == ord(' '):
|
||||
print('[**] inpainting ... ')
|
||||
with torch.no_grad():
|
||||
mask_tensor = (ToTensor()(mask)).unsqueeze(0)
|
||||
masked_tensor = (img_tensor * (1 - mask_tensor).float()) + mask_tensor
|
||||
pred_tensor = model(masked_tensor, mask_tensor)
|
||||
comp_tensor = (pred_tensor * mask_tensor + img_tensor * (1 - mask_tensor))
|
||||
|
||||
pred_np = postprocess(pred_tensor[0])
|
||||
masked_np = postprocess(masked_tensor[0])
|
||||
comp_np = postprocess(comp_tensor[0])
|
||||
|
||||
cv2.imshow('pred_images', comp_np)
|
||||
print('inpainting finish!')
|
||||
|
||||
# reset mask
|
||||
elif ch == ord('r'):
|
||||
img_tensor = (ToTensor()(orig_img) * 2.0 - 1.0).unsqueeze(0)
|
||||
image_copy[:] = orig_img.copy()
|
||||
mask[:] = 0
|
||||
sketch.show()
|
||||
print("[**] reset!")
|
||||
|
||||
# next case
|
||||
elif ch == ord('n'):
|
||||
print('[**] move to next image')
|
||||
cv2.destroyAllWindows()
|
||||
break
|
||||
|
||||
elif ch == ord('k'):
|
||||
print('[**] apply existing processing to images, and keep editing!')
|
||||
img_tensor = comp_tensor
|
||||
image_copy[:] = comp_np.copy()
|
||||
mask[:] = 0
|
||||
sketch.show()
|
||||
print("reset!")
|
||||
|
||||
elif ch == ord('+'):
|
||||
sketch.large_thick()
|
||||
|
||||
elif ch == ord('-'):
|
||||
sketch.small_thick()
|
||||
|
||||
# save results
|
||||
if ch == ord('s'):
|
||||
cv2.imwrite(os.path.join(args.outputs, f'{filename}_masked.png'), masked_np)
|
||||
cv2.imwrite(os.path.join(args.outputs, f'{filename}_pred.png'), pred_np)
|
||||
cv2.imwrite(os.path.join(args.outputs, f'{filename}_comp.png'), comp_np)
|
||||
cv2.imwrite(os.path.join(args.outputs, f'{filename}_mask.png'), mask)
|
||||
|
||||
print('[**] save successfully!')
|
||||
cv2.destroyAllWindows()
|
||||
|
||||
if ch == 27:
|
||||
break
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
demo(args)
|
||||
@ -0,0 +1,48 @@
|
||||
import argparse
|
||||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
from glob import glob
|
||||
from PIL import Image
|
||||
from multiprocessing import Pool
|
||||
|
||||
from metric import metric as module_metric
|
||||
|
||||
parser = argparse.ArgumentParser(description='Image Inpainting')
|
||||
parser.add_argument('--real_dir', required=True, type=str)
|
||||
parser.add_argument('--fake_dir', required=True, type=str)
|
||||
parser.add_argument("--metric", type=str, nargs="+")
|
||||
args = parser.parse_args()
|
||||
|
||||
|
||||
def read_img(name_pair):
|
||||
rname, fname = name_pair
|
||||
rimg = Image.open(rname)
|
||||
fimg = Image.open(fname)
|
||||
return np.array(rimg), np.array(fimg)
|
||||
|
||||
|
||||
def main(num_worker=8):
|
||||
|
||||
real_names = sorted(list(glob(f'{args.real_dir}/*.png')))
|
||||
fake_names = sorted(list(glob(f'{args.fake_dir}/*.png')))
|
||||
print(f'real images: {len(real_names)}, fake images: {len(fake_names)}')
|
||||
real_images = []
|
||||
fake_images = []
|
||||
pool = Pool(num_worker)
|
||||
for rimg, fimg in tqdm(pool.imap_unordered(read_img, zip(real_names, fake_names)), total=len(real_names), desc='loading images'):
|
||||
real_images.append(rimg)
|
||||
fake_images.append(fimg)
|
||||
|
||||
|
||||
# metrics prepare for image assesments
|
||||
metrics = {met: getattr(module_metric, met) for met in args.metric}
|
||||
evaluation_scores = {key: 0 for key,val in metrics.items()}
|
||||
for key, val in metrics.items():
|
||||
evaluation_scores[key] = val(real_images, fake_images, num_worker=num_worker)
|
||||
print(' '.join(['{}: {:6f},'.format(key, val) for key,val in evaluation_scores.items()]))
|
||||
|
||||
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
@ -0,0 +1,195 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
import torchvision.models as models
|
||||
from torch.nn.functional import conv2d
|
||||
|
||||
|
||||
class VGG19(nn.Module):
|
||||
def __init__(self, resize_input=False):
|
||||
super(VGG19, self).__init__()
|
||||
features = models.vgg19(pretrained=True).features
|
||||
|
||||
self.resize_input = resize_input
|
||||
self.mean = torch.Tensor([0.485, 0.456, 0.406]).cuda()
|
||||
self.std = torch.Tensor([0.229, 0.224, 0.225]).cuda()
|
||||
prefix = [1, 1, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5]
|
||||
posfix = [1, 2, 1, 2, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4]
|
||||
names = list(zip(prefix, posfix))
|
||||
self.relus = []
|
||||
for pre, pos in names:
|
||||
self.relus.append('relu{}_{}'.format(pre, pos))
|
||||
self.__setattr__('relu{}_{}'.format(
|
||||
pre, pos), torch.nn.Sequential())
|
||||
|
||||
nums = [[0, 1], [2, 3], [4, 5, 6], [7, 8],
|
||||
[9, 10, 11], [12, 13], [14, 15], [16, 17],
|
||||
[18, 19, 20], [21, 22], [23, 24], [25, 26],
|
||||
[27, 28, 29], [30, 31], [32, 33], [34, 35]]
|
||||
|
||||
for i, layer in enumerate(self.relus):
|
||||
for num in nums[i]:
|
||||
self.__getattr__(layer).add_module(str(num), features[num])
|
||||
|
||||
# don't need the gradients, just want the features
|
||||
for param in self.parameters():
|
||||
param.requires_grad = False
|
||||
|
||||
def forward(self, x):
|
||||
# resize and normalize input for pretrained vgg19
|
||||
x = (x + 1.0) / 2.0
|
||||
x = (x - self.mean.view(1, 3, 1, 1)) / (self.std.view(1, 3, 1, 1))
|
||||
if self.resize_input:
|
||||
x = F.interpolate(
|
||||
x, size=(256, 256), mode='bilinear', align_corners=True)
|
||||
features = []
|
||||
for layer in self.relus:
|
||||
x = self.__getattr__(layer)(x)
|
||||
features.append(x)
|
||||
out = {key: value for (key, value) in list(zip(self.relus, features))}
|
||||
return out
|
||||
|
||||
|
||||
def gaussian(window_size, sigma):
|
||||
def gauss_fcn(x):
|
||||
return -(x - window_size // 2)**2 / float(2 * sigma**2)
|
||||
gauss = torch.stack([torch.exp(torch.tensor(gauss_fcn(x)))
|
||||
for x in range(window_size)])
|
||||
return gauss / gauss.sum()
|
||||
|
||||
|
||||
def get_gaussian_kernel(kernel_size: int, sigma: float) -> torch.Tensor:
|
||||
r"""Function that returns Gaussian filter coefficients.
|
||||
Args:
|
||||
kernel_size (int): filter size. It should be odd and positive.
|
||||
sigma (float): gaussian standard deviation.
|
||||
Returns:
|
||||
Tensor: 1D tensor with gaussian filter coefficients.
|
||||
Shape:
|
||||
- Output: :math:`(\text{kernel_size})`
|
||||
|
||||
Examples::
|
||||
>>> kornia.image.get_gaussian_kernel(3, 2.5)
|
||||
tensor([0.3243, 0.3513, 0.3243])
|
||||
>>> kornia.image.get_gaussian_kernel(5, 1.5)
|
||||
tensor([0.1201, 0.2339, 0.2921, 0.2339, 0.1201])
|
||||
"""
|
||||
if not isinstance(kernel_size, int) or kernel_size % 2 == 0 or kernel_size <= 0:
|
||||
raise TypeError(
|
||||
"kernel_size must be an odd positive integer. Got {}".format(kernel_size))
|
||||
window_1d: torch.Tensor = gaussian(kernel_size, sigma)
|
||||
return window_1d
|
||||
|
||||
|
||||
def get_gaussian_kernel2d(kernel_size, sigma):
|
||||
r"""Function that returns Gaussian filter matrix coefficients.
|
||||
Args:
|
||||
kernel_size (Tuple[int, int]): filter sizes in the x and y direction.
|
||||
Sizes should be odd and positive.
|
||||
sigma (Tuple[int, int]): gaussian standard deviation in the x and y
|
||||
direction.
|
||||
Returns:
|
||||
Tensor: 2D tensor with gaussian filter matrix coefficients.
|
||||
|
||||
Shape:
|
||||
- Output: :math:`(\text{kernel_size}_x, \text{kernel_size}_y)`
|
||||
|
||||
Examples::
|
||||
>>> kornia.image.get_gaussian_kernel2d((3, 3), (1.5, 1.5))
|
||||
tensor([[0.0947, 0.1183, 0.0947],
|
||||
[0.1183, 0.1478, 0.1183],
|
||||
[0.0947, 0.1183, 0.0947]])
|
||||
|
||||
>>> kornia.image.get_gaussian_kernel2d((3, 5), (1.5, 1.5))
|
||||
tensor([[0.0370, 0.0720, 0.0899, 0.0720, 0.0370],
|
||||
[0.0462, 0.0899, 0.1123, 0.0899, 0.0462],
|
||||
[0.0370, 0.0720, 0.0899, 0.0720, 0.0370]])
|
||||
"""
|
||||
if not isinstance(kernel_size, tuple) or len(kernel_size) != 2:
|
||||
raise TypeError(
|
||||
"kernel_size must be a tuple of length two. Got {}".format(kernel_size))
|
||||
if not isinstance(sigma, tuple) or len(sigma) != 2:
|
||||
raise TypeError(
|
||||
"sigma must be a tuple of length two. Got {}".format(sigma))
|
||||
ksize_x, ksize_y = kernel_size
|
||||
sigma_x, sigma_y = sigma
|
||||
kernel_x: torch.Tensor = get_gaussian_kernel(ksize_x, sigma_x)
|
||||
kernel_y: torch.Tensor = get_gaussian_kernel(ksize_y, sigma_y)
|
||||
kernel_2d: torch.Tensor = torch.matmul(
|
||||
kernel_x.unsqueeze(-1), kernel_y.unsqueeze(-1).t())
|
||||
return kernel_2d
|
||||
|
||||
|
||||
class GaussianBlur(nn.Module):
|
||||
r"""Creates an operator that blurs a tensor using a Gaussian filter.
|
||||
The operator smooths the given tensor with a gaussian kernel by convolving
|
||||
it to each channel. It suports batched operation.
|
||||
Arguments:
|
||||
kernel_size (Tuple[int, int]): the size of the kernel.
|
||||
sigma (Tuple[float, float]): the standard deviation of the kernel.
|
||||
Returns:
|
||||
Tensor: the blurred tensor.
|
||||
Shape:
|
||||
- Input: :math:`(B, C, H, W)`
|
||||
- Output: :math:`(B, C, H, W)`
|
||||
|
||||
Examples::
|
||||
>>> input = torch.rand(2, 4, 5, 5)
|
||||
>>> gauss = kornia.filters.GaussianBlur((3, 3), (1.5, 1.5))
|
||||
>>> output = gauss(input) # 2x4x5x5
|
||||
"""
|
||||
|
||||
def __init__(self, kernel_size, sigma):
|
||||
super(GaussianBlur, self).__init__()
|
||||
self.kernel_size = kernel_size
|
||||
self.sigma = sigma
|
||||
self._padding = self.compute_zero_padding(kernel_size)
|
||||
self.kernel = get_gaussian_kernel2d(kernel_size, sigma)
|
||||
|
||||
@staticmethod
|
||||
def compute_zero_padding(kernel_size):
|
||||
"""Computes zero padding tuple."""
|
||||
computed = [(k - 1) // 2 for k in kernel_size]
|
||||
return computed[0], computed[1]
|
||||
|
||||
def forward(self, x): # type: ignore
|
||||
if not torch.is_tensor(x):
|
||||
raise TypeError(
|
||||
"Input x type is not a torch.Tensor. Got {}".format(type(x)))
|
||||
if not len(x.shape) == 4:
|
||||
raise ValueError(
|
||||
"Invalid input shape, we expect BxCxHxW. Got: {}".format(x.shape))
|
||||
# prepare kernel
|
||||
b, c, h, w = x.shape
|
||||
tmp_kernel: torch.Tensor = self.kernel.to(x.device).to(x.dtype)
|
||||
kernel: torch.Tensor = tmp_kernel.repeat(c, 1, 1, 1)
|
||||
|
||||
# TODO: explore solution when using jit.trace since it raises a warning
|
||||
# because the shape is converted to a tensor instead to a int.
|
||||
# convolve tensor with gaussian kernel
|
||||
return conv2d(x, kernel, padding=self._padding, stride=1, groups=c)
|
||||
|
||||
|
||||
######################
|
||||
# functional interface
|
||||
######################
|
||||
|
||||
def gaussian_blur(input, kernel_size, sigma):
|
||||
r"""Function that blurs a tensor using a Gaussian filter.
|
||||
See :class:`~kornia.filters.GaussianBlur` for details.
|
||||
"""
|
||||
return GaussianBlur(kernel_size, sigma)(input)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
img = Image.open('test.png').convert('L')
|
||||
tensor_img = F.to_tensor(img).unsqueeze(0).float()
|
||||
print('tensor_img size: ', tensor_img.size())
|
||||
|
||||
blurred_img = gaussian_blur(tensor_img, (61, 61), (10, 10))
|
||||
print(torch.min(blurred_img), torch.max(blurred_img))
|
||||
|
||||
blurred_img = blurred_img*255
|
||||
img = blurred_img.int().numpy().astype(np.uint8)[0][0]
|
||||
print(img.shape, np.min(img), np.max(img), np.unique(img))
|
||||
cv2.imwrite('gaussian.png', img)
|
||||
@ -0,0 +1,104 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from .common import VGG19, gaussian_blur
|
||||
|
||||
|
||||
|
||||
class L1():
|
||||
def __init__(self,):
|
||||
self.calc = torch.nn.L1Loss()
|
||||
|
||||
def __call__(self, x, y):
|
||||
return self.calc(x, y)
|
||||
|
||||
|
||||
class Perceptual(nn.Module):
|
||||
def __init__(self, weights=[1.0, 1.0, 1.0, 1.0, 1.0]):
|
||||
super(Perceptual, self).__init__()
|
||||
self.vgg = VGG19().cuda()
|
||||
self.criterion = torch.nn.L1Loss()
|
||||
self.weights = weights
|
||||
|
||||
def __call__(self, x, y):
|
||||
x_vgg, y_vgg = self.vgg(x), self.vgg(y)
|
||||
content_loss = 0.0
|
||||
prefix = [1, 2, 3, 4, 5]
|
||||
for i in range(5):
|
||||
content_loss += self.weights[i] * self.criterion(
|
||||
x_vgg[f'relu{prefix[i]}_1'], y_vgg[f'relu{prefix[i]}_1'])
|
||||
return content_loss
|
||||
|
||||
|
||||
class Style(nn.Module):
|
||||
def __init__(self):
|
||||
super(Style, self).__init__()
|
||||
self.vgg = VGG19().cuda()
|
||||
self.criterion = torch.nn.L1Loss()
|
||||
|
||||
def compute_gram(self, x):
|
||||
b, c, h, w = x.size()
|
||||
f = x.view(b, c, w * h)
|
||||
f_T = f.transpose(1, 2)
|
||||
G = f.bmm(f_T) / (h * w * c)
|
||||
return G
|
||||
|
||||
def __call__(self, x, y):
|
||||
x_vgg, y_vgg = self.vgg(x), self.vgg(y)
|
||||
style_loss = 0.0
|
||||
prefix = [2, 3, 4, 5]
|
||||
posfix = [2, 4, 4, 2]
|
||||
for pre, pos in list(zip(prefix, posfix)):
|
||||
style_loss += self.criterion(
|
||||
self.compute_gram(x_vgg[f'relu{pre}_{pos}']), self.compute_gram(y_vgg[f'relu{pre}_{pos}']))
|
||||
return style_loss
|
||||
|
||||
|
||||
class nsgan():
|
||||
def __init__(self, ):
|
||||
self.loss_fn = torch.nn.Softplus()
|
||||
|
||||
def __call__(self, netD, fake, real):
|
||||
fake_detach = fake.detach()
|
||||
d_fake = netD(fake_detach)
|
||||
d_real = netD(real)
|
||||
dis_loss = self.loss_fn(-d_real).mean() + self.loss_fn(d_fake).mean()
|
||||
|
||||
g_fake = netD(fake)
|
||||
gen_loss = self.loss_fn(-g_fake).mean()
|
||||
|
||||
return dis_loss, gen_loss
|
||||
|
||||
|
||||
class smgan():
|
||||
def __init__(self, ksize=71):
|
||||
self.ksize = ksize
|
||||
self.loss_fn = nn.MSELoss()
|
||||
|
||||
def __call__(self, netD, fake, real, masks):
|
||||
fake_detach = fake.detach()
|
||||
|
||||
g_fake = netD(fake)
|
||||
d_fake = netD(fake_detach)
|
||||
d_real = netD(real)
|
||||
|
||||
_, _, h, w = g_fake.size()
|
||||
b, c, ht, wt = masks.size()
|
||||
|
||||
# Handle inconsistent size between outputs and masks
|
||||
if h != ht or w != wt:
|
||||
g_fake = F.interpolate(g_fake, size=(ht, wt), mode='bilinear', align_corners=True)
|
||||
d_fake = F.interpolate(d_fake, size=(ht, wt), mode='bilinear', align_corners=True)
|
||||
d_real = F.interpolate(d_real, size=(ht, wt), mode='bilinear', align_corners=True)
|
||||
d_fake_label = gaussian_blur(masks, (self.ksize, self.ksize), (10, 10)).detach().cuda()
|
||||
d_real_label = torch.zeros_like(d_real).cuda()
|
||||
g_fake_label = torch.ones_like(g_fake).cuda()
|
||||
|
||||
dis_loss = self.loss_fn(d_fake, d_fake_label) + self.loss_fn(d_real, d_real_label)
|
||||
gen_loss = self.loss_fn(g_fake, g_fake_label) * masks / torch.mean(masks)
|
||||
|
||||
return dis_loss.mean(), gen_loss.mean()
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,130 @@
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from torchvision import models
|
||||
|
||||
|
||||
class InceptionV3(nn.Module):
|
||||
"""Pretrained InceptionV3 network returning feature maps"""
|
||||
# Index of default block of inception to return,
|
||||
# corresponds to output of final average pooling
|
||||
DEFAULT_BLOCK_INDEX = 3
|
||||
|
||||
# Maps feature dimensionality to their output blocks indices
|
||||
BLOCK_INDEX_BY_DIM = {
|
||||
64: 0, # First max pooling features
|
||||
192: 1, # Second max pooling featurs
|
||||
768: 2, # Pre-aux classifier features
|
||||
2048: 3 # Final average pooling features
|
||||
}
|
||||
|
||||
def __init__(self, output_blocks=[DEFAULT_BLOCK_INDEX],
|
||||
resize_input=True, normalize_input=True, requires_grad=False):
|
||||
"""Build pretrained InceptionV3
|
||||
Parameters
|
||||
----------
|
||||
output_blocks : list of int
|
||||
Indices of blocks to return features of. Possible values are:
|
||||
- 0: corresponds to output of first max pooling
|
||||
- 1: corresponds to output of second max pooling
|
||||
- 2: corresponds to output which is fed to aux classifier
|
||||
- 3: corresponds to output of final average pooling
|
||||
resize_input : bool
|
||||
If true, bilinearly resizes input to width and height 299 before
|
||||
feeding input to model. As the network without fully connected
|
||||
layers is fully convolutional, it should be able to handle inputs
|
||||
of arbitrary size, so resizing might not be strictly needed
|
||||
normalize_input : bool
|
||||
If true, normalizes the input to the statistics the pretrained
|
||||
Inception network expects
|
||||
requires_grad : bool
|
||||
If true, parameters of the model require gradient. Possibly useful
|
||||
for finetuning the network
|
||||
"""
|
||||
super(InceptionV3, self).__init__()
|
||||
self.resize_input = resize_input
|
||||
self.normalize_input = normalize_input
|
||||
self.output_blocks = sorted(output_blocks)
|
||||
self.last_needed_block = max(output_blocks)
|
||||
|
||||
assert self.last_needed_block <= 3, \
|
||||
'Last possible output block index is 3'
|
||||
|
||||
self.blocks = nn.ModuleList()
|
||||
inception = models.inception_v3(pretrained=True)
|
||||
|
||||
# Block 0: input to maxpool1
|
||||
block0 = [
|
||||
inception.Conv2d_1a_3x3,
|
||||
inception.Conv2d_2a_3x3,
|
||||
inception.Conv2d_2b_3x3,
|
||||
nn.MaxPool2d(kernel_size=3, stride=2)
|
||||
]
|
||||
self.blocks.append(nn.Sequential(*block0))
|
||||
|
||||
# Block 1: maxpool1 to maxpool2
|
||||
if self.last_needed_block >= 1:
|
||||
block1 = [
|
||||
inception.Conv2d_3b_1x1,
|
||||
inception.Conv2d_4a_3x3,
|
||||
nn.MaxPool2d(kernel_size=3, stride=2)
|
||||
]
|
||||
self.blocks.append(nn.Sequential(*block1))
|
||||
|
||||
# Block 2: maxpool2 to aux classifier
|
||||
if self.last_needed_block >= 2:
|
||||
block2 = [
|
||||
inception.Mixed_5b,
|
||||
inception.Mixed_5c,
|
||||
inception.Mixed_5d,
|
||||
inception.Mixed_6a,
|
||||
inception.Mixed_6b,
|
||||
inception.Mixed_6c,
|
||||
inception.Mixed_6d,
|
||||
inception.Mixed_6e,
|
||||
]
|
||||
self.blocks.append(nn.Sequential(*block2))
|
||||
|
||||
# Block 3: aux classifier to final avgpool
|
||||
if self.last_needed_block >= 3:
|
||||
block3 = [
|
||||
inception.Mixed_7a,
|
||||
inception.Mixed_7b,
|
||||
inception.Mixed_7c,
|
||||
nn.AdaptiveAvgPool2d(output_size=(1, 1))
|
||||
]
|
||||
self.blocks.append(nn.Sequential(*block3))
|
||||
|
||||
for param in self.parameters():
|
||||
param.requires_grad = requires_grad
|
||||
|
||||
def forward(self, inp):
|
||||
"""Get Inception feature maps
|
||||
Parameters
|
||||
----------
|
||||
inp : torch.autograd.Variable
|
||||
Input tensor of shape Bx3xHxW. Values are expected to be in
|
||||
range (0, 1)
|
||||
Returns
|
||||
-------
|
||||
List of torch.autograd.Variable, corresponding to the selected output
|
||||
block, sorted ascending by index
|
||||
"""
|
||||
outp = []
|
||||
x = inp
|
||||
if self.resize_input:
|
||||
x = F.interpolate(x, size=(299, 299),
|
||||
mode='bilinear', align_corners=True)
|
||||
|
||||
if self.normalize_input:
|
||||
x = x.clone()
|
||||
x[:, 0] = x[:, 0] * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
|
||||
x[:, 1] = x[:, 1] * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
|
||||
x[:, 2] = x[:, 2] * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
|
||||
|
||||
for idx, block in enumerate(self.blocks):
|
||||
x = block(x)
|
||||
if idx in self.output_blocks:
|
||||
outp.append(x)
|
||||
if idx == self.last_needed_block:
|
||||
break
|
||||
return outp
|
||||
@ -0,0 +1,212 @@
|
||||
import os
|
||||
import pickle
|
||||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
from scipy import linalg
|
||||
from multiprocessing import Pool
|
||||
from skimage.metrics import structural_similarity
|
||||
from skimage.metrics import peak_signal_noise_ratio
|
||||
|
||||
import torch
|
||||
from torch.autograd import Variable
|
||||
from torch.nn.functional import adaptive_avg_pool2d
|
||||
|
||||
from .inception import InceptionV3
|
||||
|
||||
|
||||
|
||||
# ============================
|
||||
|
||||
def compare_mae(pairs):
|
||||
real, fake = pairs
|
||||
real, fake = real.astype(np.float32), fake.astype(np.float32)
|
||||
return np.sum(np.abs(real - fake)) / np.sum(real + fake)
|
||||
|
||||
def compare_psnr(pairs):
|
||||
real, fake = pairs
|
||||
return peak_signal_noise_ratio(real, fake)
|
||||
|
||||
def compare_ssim(pairs):
|
||||
real, fake = pairs
|
||||
return structural_similarity(real, fake, multichannel=True)
|
||||
|
||||
# ================================
|
||||
|
||||
def mae(reals, fakes, num_worker=8):
|
||||
error = 0
|
||||
pool = Pool(num_worker)
|
||||
for val in tqdm(pool.imap_unordered(compare_mae, zip(reals, fakes)), total=len(reals), desc='compare_mae'):
|
||||
error += val
|
||||
return error / len(reals)
|
||||
|
||||
def psnr(reals, fakes, num_worker=8):
|
||||
error = 0
|
||||
pool = Pool(num_worker)
|
||||
for val in tqdm(pool.imap_unordered(compare_psnr, zip(reals, fakes)), total=len(reals), desc='compare_psnr'):
|
||||
error += val
|
||||
return error / len(reals)
|
||||
|
||||
def ssim(reals, fakes, num_worker=8):
|
||||
error = 0
|
||||
pool = Pool(num_worker)
|
||||
for val in tqdm(pool.imap_unordered(compare_ssim, zip(reals, fakes)), total=len(reals), desc='compare_ssim'):
|
||||
error += val
|
||||
return error / len(reals)
|
||||
|
||||
def fid(reals, fakes, num_worker=8, real_fid_path=None):
|
||||
|
||||
dims = 2048
|
||||
batch_size = 4
|
||||
block_idx = InceptionV3.BLOCK_INDEX_BY_DIM[dims]
|
||||
model = InceptionV3([block_idx]).cuda()
|
||||
|
||||
if real_fid_path is None:
|
||||
real_fid_path = 'places2_fid.pt'
|
||||
|
||||
if os.path.isfile(real_fid_path):
|
||||
data = pickle.load(open(real_fid_path, 'rb'))
|
||||
real_m, real_s = data['mu'], data['sigma']
|
||||
else:
|
||||
reals = (np.array(reals).astype(np.float32) / 255.0).transpose((0, 3, 1, 2))
|
||||
real_m, real_s = calculate_activation_statistics(reals, model, batch_size, dims)
|
||||
with open(real_fid_path, 'wb') as f:
|
||||
pickle.dump({'mu': real_m, 'sigma': real_s}, f)
|
||||
|
||||
|
||||
# calculate fid statistics for fake images
|
||||
fakes = (np.array(fakes).astype(np.float32) / 255.0).transpose((0, 3, 1, 2))
|
||||
fake_m, fake_s = calculate_activation_statistics(fakes, model, batch_size, dims)
|
||||
|
||||
fid_value = calculate_frechet_distance(real_m, real_s, fake_m, fake_s)
|
||||
|
||||
return fid_value
|
||||
|
||||
|
||||
def calculate_activation_statistics(images, model, batch_size=64,
|
||||
dims=2048, cuda=True, verbose=False):
|
||||
"""Calculation of the statistics used by the FID.
|
||||
Params:
|
||||
-- images : Numpy array of dimension (n_images, 3, hi, wi). The values
|
||||
must lie between 0 and 1.
|
||||
-- model : Instance of inception model
|
||||
-- batch_size : The images numpy array is split into batches with
|
||||
batch size batch_size. A reasonable batch size
|
||||
depends on the hardware.
|
||||
-- dims : Dimensionality of features returned by Inception
|
||||
-- cuda : If set to True, use GPU
|
||||
-- verbose : If set to True and parameter out_step is given, the
|
||||
number of calculated batches is reported.
|
||||
Returns:
|
||||
-- mu : The mean over samples of the activations of the pool_3 layer of
|
||||
the inception model.
|
||||
-- sigma : The covariance matrix of the activations of the pool_3 layer of
|
||||
the inception model.
|
||||
"""
|
||||
act = get_activations(images, model, batch_size, dims, cuda, verbose)
|
||||
mu = np.mean(act, axis=0)
|
||||
sigma = np.cov(act, rowvar=False)
|
||||
return mu, sigma
|
||||
|
||||
|
||||
def get_activations(images, model, batch_size=64, dims=2048, cuda=True, verbose=False):
|
||||
"""Calculates the activations of the pool_3 layer for all images.
|
||||
Params:
|
||||
-- images : Numpy array of dimension (n_images, 3, hi, wi). The values
|
||||
must lie between 0 and 1.
|
||||
-- model : Instance of inception model
|
||||
-- batch_size : the images numpy array is split into batches with
|
||||
batch size batch_size. A reasonable batch size depends
|
||||
on the hardware.
|
||||
-- dims : Dimensionality of features returned by Inception
|
||||
-- cuda : If set to True, use GPU
|
||||
-- verbose : If set to True and parameter out_step is given, the number
|
||||
of calculated batches is reported.
|
||||
Returns:
|
||||
-- A numpy array of dimension (num images, dims) that contains the
|
||||
activations of the given tensor when feeding inception with the
|
||||
query tensor.
|
||||
"""
|
||||
model.eval()
|
||||
|
||||
d0 = images.shape[0]
|
||||
if batch_size > d0:
|
||||
print(('Warning: batch size is bigger than the data size. '
|
||||
'Setting batch size to data size'))
|
||||
batch_size = d0
|
||||
|
||||
n_batches = d0 // batch_size
|
||||
n_used_imgs = n_batches * batch_size
|
||||
|
||||
pred_arr = np.empty((n_used_imgs, dims))
|
||||
for i in tqdm(range(n_batches), desc='calculate activations'):
|
||||
if verbose:
|
||||
print('\rPropagating batch %d/%d' %
|
||||
(i + 1, n_batches), end='', flush=True)
|
||||
start = i * batch_size
|
||||
end = start + batch_size
|
||||
|
||||
batch = torch.from_numpy(images[start:end]).type(torch.FloatTensor)
|
||||
batch = Variable(batch)
|
||||
if torch.cuda.is_available:
|
||||
batch = batch.cuda()
|
||||
with torch.no_grad():
|
||||
pred = model(batch)[0]
|
||||
|
||||
# If model output is not scalar, apply global spatial average pooling.
|
||||
# This happens if you choose a dimensionality not equal 2048.
|
||||
if pred.shape[2] != 1 or pred.shape[3] != 1:
|
||||
pred = adaptive_avg_pool2d(pred, output_size=(1, 1))
|
||||
pred_arr[start:end] = pred.cpu().data.numpy().reshape(batch_size, -1)
|
||||
if verbose:
|
||||
print(' done')
|
||||
|
||||
return pred_arr
|
||||
|
||||
|
||||
def calculate_frechet_distance(mu1, sigma1, mu2, sigma2, eps=1e-6):
|
||||
"""Numpy implementation of the Frechet Distance.
|
||||
The Frechet distance between two multivariate Gaussians X_1 ~ N(mu_1, C_1)
|
||||
and X_2 ~ N(mu_2, C_2) is
|
||||
d^2 = ||mu_1 - mu_2||^2 + Tr(C_1 + C_2 - 2*sqrt(C_1*C_2)).
|
||||
Stable version by Dougal J. Sutherland.
|
||||
Params:
|
||||
-- mu1 : Numpy array containing the activations of a layer of the
|
||||
inception net (like returned by the function 'get_predictions')
|
||||
for generated samples.
|
||||
-- mu2 : The sample mean over activations, precalculated on an
|
||||
representive data set.
|
||||
-- sigma1: The covariance matrix over activations for generated samples.
|
||||
-- sigma2: The covariance matrix over activations, precalculated on an
|
||||
representive data set.
|
||||
Returns:
|
||||
-- : The Frechet Distance.
|
||||
"""
|
||||
|
||||
mu1 = np.atleast_1d(mu1)
|
||||
mu2 = np.atleast_1d(mu2)
|
||||
|
||||
sigma1 = np.atleast_2d(sigma1)
|
||||
sigma2 = np.atleast_2d(sigma2)
|
||||
|
||||
assert mu1.shape == mu2.shape, 'Training and test mean vectors have different lengths'
|
||||
assert sigma1.shape == sigma2.shape, 'Training and test covariances have different dimensions'
|
||||
diff = mu1 - mu2
|
||||
|
||||
# Product might be almost singular
|
||||
covmean, _ = linalg.sqrtm(sigma1.dot(sigma2), disp=False)
|
||||
if not np.isfinite(covmean).all():
|
||||
msg = ('fid calculation produces singular product; '
|
||||
'adding %s to diagonal of cov estimates') % eps
|
||||
print(msg)
|
||||
offset = np.eye(sigma1.shape[0]) * eps
|
||||
covmean = linalg.sqrtm((sigma1 + offset).dot(sigma2 + offset))
|
||||
|
||||
# Numerical error might give slight imaginary component
|
||||
if np.iscomplexobj(covmean):
|
||||
if not np.allclose(np.diagonal(covmean).imag, 0, atol=1e-3):
|
||||
m = np.max(np.abs(covmean.imag))
|
||||
raise ValueError('Imaginary component {}'.format(m))
|
||||
covmean = covmean.real
|
||||
tr_covmean = np.trace(covmean)
|
||||
|
||||
return (diff.dot(diff) + np.trace(sigma1) + np.trace(sigma2) - 2 * tr_covmean)
|
||||
@ -0,0 +1,113 @@
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from torch.nn.utils import spectral_norm
|
||||
|
||||
from .common import BaseNetwork
|
||||
|
||||
|
||||
class InpaintGenerator(BaseNetwork):
|
||||
def __init__(self, args): # 1046
|
||||
super(InpaintGenerator, self).__init__()
|
||||
|
||||
self.encoder = nn.Sequential(
|
||||
nn.ReflectionPad2d(3),
|
||||
nn.Conv2d(4, 64, 7),
|
||||
nn.ReLU(True),
|
||||
nn.Conv2d(64, 128, 4, stride=2, padding=1),
|
||||
nn.ReLU(True),
|
||||
nn.Conv2d(128, 256, 4, stride=2, padding=1),
|
||||
nn.ReLU(True)
|
||||
)
|
||||
|
||||
self.middle = nn.Sequential(*[AOTBlock(256, args.rates) for _ in range(args.block_num)])
|
||||
|
||||
self.decoder = nn.Sequential(
|
||||
UpConv(256, 128),
|
||||
nn.ReLU(True),
|
||||
UpConv(128, 64),
|
||||
nn.ReLU(True),
|
||||
nn.Conv2d(64, 3, 3, stride=1, padding=1)
|
||||
)
|
||||
|
||||
self.init_weights()
|
||||
|
||||
def forward(self, x, mask):
|
||||
x = torch.cat([x, mask], dim=1)
|
||||
x = self.encoder(x)
|
||||
x = self.middle(x)
|
||||
x = self.decoder(x)
|
||||
x = torch.tanh(x)
|
||||
return x
|
||||
|
||||
|
||||
class UpConv(nn.Module):
|
||||
def __init__(self, inc, outc, scale=2):
|
||||
super(UpConv, self).__init__()
|
||||
self.scale = scale
|
||||
self.conv = nn.Conv2d(inc, outc, 3, stride=1, padding=1)
|
||||
|
||||
def forward(self, x):
|
||||
return self.conv(F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=True))
|
||||
|
||||
|
||||
class AOTBlock(nn.Module):
|
||||
def __init__(self, dim, rates):
|
||||
super(AOTBlock, self).__init__()
|
||||
self.rates = rates
|
||||
for i, rate in enumerate(rates):
|
||||
self.__setattr__(
|
||||
'block{}'.format(str(i).zfill(2)),
|
||||
nn.Sequential(
|
||||
nn.ReflectionPad2d(rate),
|
||||
nn.Conv2d(dim, dim//4, 3, padding=0, dilation=rate),
|
||||
nn.ReLU(True)))
|
||||
self.fuse = nn.Sequential(
|
||||
nn.ReflectionPad2d(1),
|
||||
nn.Conv2d(dim, dim, 3, padding=0, dilation=1))
|
||||
self.gate = nn.Sequential(
|
||||
nn.ReflectionPad2d(1),
|
||||
nn.Conv2d(dim, dim, 3, padding=0, dilation=1))
|
||||
|
||||
def forward(self, x):
|
||||
out = [self.__getattr__(f'block{str(i).zfill(2)}')(x) for i in range(len(self.rates))]
|
||||
out = torch.cat(out, 1)
|
||||
out = self.fuse(out)
|
||||
mask = my_layer_norm(self.gate(x))
|
||||
mask = torch.sigmoid(mask)
|
||||
return x * (1 - mask) + out * mask
|
||||
|
||||
|
||||
def my_layer_norm(feat):
|
||||
mean = feat.mean((2, 3), keepdim=True)
|
||||
std = feat.std((2, 3), keepdim=True) + 1e-9
|
||||
feat = 2 * (feat - mean) / std - 1
|
||||
feat = 5 * feat
|
||||
return feat
|
||||
|
||||
|
||||
|
||||
|
||||
# ----- discriminator -----
|
||||
class Discriminator(BaseNetwork):
|
||||
def __init__(self, ):
|
||||
super(Discriminator, self).__init__()
|
||||
inc = 3
|
||||
self.conv = nn.Sequential(
|
||||
spectral_norm(nn.Conv2d(inc, 64, 4, stride=2, padding=1, bias=False)),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
spectral_norm(nn.Conv2d(64, 128, 4, stride=2, padding=1, bias=False)),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
spectral_norm(nn.Conv2d(128, 256, 4, stride=2, padding=1, bias=False)),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
spectral_norm(nn.Conv2d(256, 512, 4, stride=1, padding=1, bias=False)),
|
||||
nn.LeakyReLU(0.2, inplace=True),
|
||||
nn.Conv2d(512, 1, 4, stride=1, padding=1)
|
||||
)
|
||||
|
||||
self.init_weights()
|
||||
|
||||
def forward(self, x):
|
||||
feat = self.conv(x)
|
||||
return feat
|
||||
|
||||
@ -0,0 +1,57 @@
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
|
||||
class BaseNetwork(nn.Module):
|
||||
def __init__(self):
|
||||
super(BaseNetwork, self).__init__()
|
||||
|
||||
def print_network(self):
|
||||
if isinstance(self, list):
|
||||
self = self[0]
|
||||
num_params = 0
|
||||
for param in self.parameters():
|
||||
num_params += param.numel()
|
||||
print('Network [%s] was created. Total number of parameters: %.1f million. '
|
||||
'To see the architecture, do print(network).' % (type(self).__name__, num_params / 1000000))
|
||||
|
||||
def init_weights(self, init_type='normal', gain=0.02):
|
||||
'''
|
||||
initialize network's weights
|
||||
init_type: normal | xavier | kaiming | orthogonal
|
||||
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/9451e70673400885567d08a9e97ade2524c700d0/models/networks.py#L39
|
||||
'''
|
||||
def init_func(m):
|
||||
classname = m.__class__.__name__
|
||||
if classname.find('InstanceNorm2d') != -1:
|
||||
if hasattr(m, 'weight') and m.weight is not None:
|
||||
nn.init.constant_(m.weight.data, 1.0)
|
||||
if hasattr(m, 'bias') and m.bias is not None:
|
||||
nn.init.constant_(m.bias.data, 0.0)
|
||||
elif hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
|
||||
if init_type == 'normal':
|
||||
nn.init.normal_(m.weight.data, 0.0, gain)
|
||||
elif init_type == 'xavier':
|
||||
nn.init.xavier_normal_(m.weight.data, gain=gain)
|
||||
elif init_type == 'xavier_uniform':
|
||||
nn.init.xavier_uniform_(m.weight.data, gain=1.0)
|
||||
elif init_type == 'kaiming':
|
||||
nn.init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
|
||||
elif init_type == 'orthogonal':
|
||||
nn.init.orthogonal_(m.weight.data, gain=gain)
|
||||
elif init_type == 'none': # uses pytorch's default init method
|
||||
m.reset_parameters()
|
||||
else:
|
||||
raise NotImplementedError(
|
||||
'initialization method [%s] is not implemented' % init_type)
|
||||
if hasattr(m, 'bias') and m.bias is not None:
|
||||
nn.init.constant_(m.bias.data, 0.0)
|
||||
|
||||
self.apply(init_func)
|
||||
|
||||
# propagate to children
|
||||
for m in self.children():
|
||||
if hasattr(m, 'init_weights'):
|
||||
m.init_weights(init_type, gain)
|
||||
|
||||
@ -0,0 +1,62 @@
|
||||
import os
|
||||
import argparse
|
||||
import importlib
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
from glob import glob
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from torchvision.transforms import ToTensor
|
||||
|
||||
from utils.option import args
|
||||
|
||||
|
||||
def postprocess(image):
|
||||
image = torch.clamp(image, -1., 1.)
|
||||
image = (image + 1) / 2.0 * 255.0
|
||||
image = image.permute(1, 2, 0)
|
||||
image = image.cpu().numpy().astype(np.uint8)
|
||||
return Image.fromarray(image)
|
||||
|
||||
|
||||
def main_worker(args, use_gpu=True):
|
||||
|
||||
device = torch.device('cuda') if use_gpu else torch.device('cpu')
|
||||
|
||||
# Model and version
|
||||
net = importlib.import_module('model.'+args.model)
|
||||
model = net.InpaintGenerator(args).cuda()
|
||||
model.load_state_dict(torch.load(args.pre_train, map_location='cuda'))
|
||||
model.eval()
|
||||
|
||||
# prepare dataset
|
||||
image_paths = []
|
||||
for ext in ['.jpg', '.png']:
|
||||
image_paths.extend(glob(os.path.join(args.dir_image, '*'+ext)))
|
||||
image_paths.sort()
|
||||
mask_paths = sorted(glob(os.path.join(args.dir_mask, '*.png')))
|
||||
os.makedirs(args.outputs, exist_ok=True)
|
||||
|
||||
# iteration through datasets
|
||||
for ipath, mpath in zip(image_paths, mask_paths):
|
||||
image = ToTensor()(Image.open(ipath).convert('RGB'))
|
||||
image = (image * 2.0 - 1.0).unsqueeze(0)
|
||||
mask = ToTensor()(Image.open(mpath).convert('L'))
|
||||
mask = mask.unsqueeze(0)
|
||||
image, mask = image.cuda(), mask.cuda()
|
||||
image_masked = image * (1 - mask.float()) + mask
|
||||
|
||||
with torch.no_grad():
|
||||
pred_img = model(image_masked, mask)
|
||||
|
||||
comp_imgs = (1 - mask) * image + mask * pred_img
|
||||
image_name = os.path.basename(ipath).split('.')[0]
|
||||
postprocess(image_masked[0]).save(os.path.join(args.outputs, f'{image_name}_masked.png'))
|
||||
postprocess(pred_img[0]).save(os.path.join(args.outputs, f'{image_name}_pred.png'))
|
||||
postprocess(comp_imgs[0]).save(os.path.join(args.outputs, f'{image_name}_comp.png'))
|
||||
print(f'saving to {os.path.join(args.outputs, image_name)}')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main_worker(args)
|
||||
@ -0,0 +1,51 @@
|
||||
import os
|
||||
import torch
|
||||
import torch.multiprocessing as mp
|
||||
|
||||
|
||||
from utils.option import args
|
||||
from trainer.trainer import Trainer
|
||||
|
||||
|
||||
def main_worker(id, ngpus_per_node, args):
|
||||
args.local_rank = args.global_rank = id
|
||||
if args.distributed:
|
||||
torch.cuda.set_device(args.local_rank)
|
||||
print(f'using GPU {args.world_size}-{args.global_rank} for training')
|
||||
torch.distributed.init_process_group(
|
||||
backend='nccl', init_method=args.init_method,
|
||||
world_size=args.world_size, rank=args.global_rank,
|
||||
group_name='mtorch')
|
||||
|
||||
args.save_dir = os.path.join(
|
||||
args.save_dir, f'{args.model}_{args.data_train}_{args.mask_type}{args.image_size}')
|
||||
|
||||
if (not args.distributed) or args.global_rank == 0:
|
||||
os.makedirs(args.save_dir, exist_ok=True)
|
||||
with open(os.path.join(args.save_dir, 'config.txt'), 'a') as f:
|
||||
for key, val in vars(args).items():
|
||||
f.write(f'{key}: {val}\n')
|
||||
print(f'[**] create folder {args.save_dir}')
|
||||
|
||||
trainer = Trainer(args)
|
||||
trainer.train()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
torch.manual_seed(args.seed)
|
||||
torch.backends.cudnn.enabled = True
|
||||
torch.backends.cudnn.benchmark = True
|
||||
|
||||
# setup distributed parallel training environments
|
||||
ngpus_per_node = torch.cuda.device_count()
|
||||
if ngpus_per_node > 1:
|
||||
args.world_size = ngpus_per_node
|
||||
args.init_method = f'tcp://127.0.0.1:{args.port}'
|
||||
args.distributed = True
|
||||
mp.spawn(main_worker, nprocs=ngpus_per_node,
|
||||
args=(ngpus_per_node, args))
|
||||
else:
|
||||
args.world_size = 1
|
||||
args.distributed = False
|
||||
main_worker(0, 1, args)
|
||||
@ -0,0 +1,58 @@
|
||||
import time
|
||||
import numpy as np
|
||||
|
||||
import torch
|
||||
from torch import distributed as dist
|
||||
|
||||
|
||||
class timer():
|
||||
def __init__(self):
|
||||
self.acc = 0
|
||||
self.t0 = torch.cuda.Event(enable_timing=True)
|
||||
self.t1 = torch.cuda.Event(enable_timing=True)
|
||||
self.tic()
|
||||
|
||||
def tic(self):
|
||||
self.t0.record()
|
||||
|
||||
def toc(self, restart=False):
|
||||
self.t1.record()
|
||||
torch.cuda.synchronize()
|
||||
diff = self.t0.elapsed_time(self.t1) /1000.
|
||||
if restart: self.tic()
|
||||
return diff
|
||||
|
||||
def hold(self):
|
||||
self.acc += self.toc()
|
||||
|
||||
def release(self):
|
||||
ret = self.acc
|
||||
self.acc = 0
|
||||
|
||||
return ret
|
||||
|
||||
def reset(self):
|
||||
self.acc = 0
|
||||
|
||||
|
||||
def reduce_loss_dict(loss_dict, world_size):
|
||||
if world_size == 1:
|
||||
return loss_dict
|
||||
|
||||
with torch.no_grad():
|
||||
keys = []
|
||||
losses = []
|
||||
|
||||
for k in sorted(loss_dict.keys()):
|
||||
keys.append(k)
|
||||
losses.append(loss_dict[k])
|
||||
|
||||
losses = torch.stack(losses, 0)
|
||||
dist.reduce(losses, dst=0)
|
||||
|
||||
if dist.get_rank() == 0:
|
||||
losses /= world_size
|
||||
|
||||
reduced_losses = {k: v for k, v in zip(keys, losses)}
|
||||
return reduced_losses
|
||||
|
||||
@ -0,0 +1,153 @@
|
||||
import os
|
||||
import importlib
|
||||
from tqdm import tqdm
|
||||
from glob import glob
|
||||
|
||||
import torch
|
||||
import torch.optim as optim
|
||||
from torchvision.utils import make_grid
|
||||
from torch.utils.tensorboard import SummaryWriter
|
||||
from torch.nn.parallel import DistributedDataParallel as DDP
|
||||
|
||||
from data import create_loader
|
||||
from loss import loss as loss_module
|
||||
from .common import timer, reduce_loss_dict
|
||||
|
||||
|
||||
class Trainer():
|
||||
def __init__(self, args):
|
||||
self.args = args
|
||||
self.iteration = 0
|
||||
|
||||
# setup data set and data loader
|
||||
self.dataloader = create_loader(args)
|
||||
|
||||
# set up losses and metrics
|
||||
self.rec_loss_func = {
|
||||
key: getattr(loss_module, key)() for key, val in args.rec_loss.items()}
|
||||
self.adv_loss = getattr(loss_module, args.gan_type)()
|
||||
|
||||
# Image generator input: [rgb(3) + mask(1)], discriminator input: [rgb(3)]
|
||||
net = importlib.import_module('model.'+args.model)
|
||||
|
||||
self.netG = net.InpaintGenerator(args).cuda()
|
||||
self.optimG = torch.optim.Adam(
|
||||
self.netG.parameters(), lr=args.lrg, betas=(args.beta1, args.beta2))
|
||||
|
||||
self.netD = net.Discriminator().cuda()
|
||||
self.optimD = torch.optim.Adam(
|
||||
self.netD.parameters(), lr=args.lrd, betas=(args.beta1, args.beta2))
|
||||
|
||||
self.load()
|
||||
if args.distributed:
|
||||
self.netG = DDP(self.netG, device_ids= [args.local_rank], output_device=[args.local_rank])
|
||||
self.netD = DDP(self.netD, device_ids= [args.local_rank], output_device=[args.local_rank])
|
||||
|
||||
if args.tensorboard:
|
||||
self.writer = SummaryWriter(os.path.join(args.save_dir, 'log'))
|
||||
|
||||
|
||||
def load(self):
|
||||
try:
|
||||
gpath = sorted(list(glob(os.path.join(self.args.save_dir, 'G*.pt'))))[-1]
|
||||
self.netG.load_state_dict(torch.load(gpath, map_location='cuda'))
|
||||
self.iteration = int(os.path.basename(gpath)[1:-3])
|
||||
if self.args.global_rank == 0:
|
||||
print(f'[**] Loading generator network from {gpath}')
|
||||
except:
|
||||
pass
|
||||
|
||||
try:
|
||||
dpath = sorted(list(glob(os.path.join(self.args.save_dir, 'D*.pt'))))[-1]
|
||||
self.netD.load_state_dict(torch.load(dpath, map_location='cuda'))
|
||||
if self.args.global_rank == 0:
|
||||
print(f'[**] Loading discriminator network from {dpath}')
|
||||
except:
|
||||
pass
|
||||
|
||||
try:
|
||||
opath = sorted(list(glob(os.path.join(self.args.save_dir, 'O*.pt'))))[-1]
|
||||
data = torch.load(opath, map_location='cuda')
|
||||
self.optimG.load_state_dict(data['optimG'])
|
||||
self.optimD.load_state_dict(data['optimD'])
|
||||
if self.args.global_rank == 0:
|
||||
print(f'[**] Loading optimizer from {opath}')
|
||||
except:
|
||||
pass
|
||||
|
||||
|
||||
def save(self, ):
|
||||
if self.args.global_rank == 0:
|
||||
print(f'\nsaving {self.iteration} model to {self.args.save_dir} ...')
|
||||
torch.save(self.netG.module.state_dict(),
|
||||
os.path.join(self.args.save_dir, f'G{str(self.iteration).zfill(7)}.pt'))
|
||||
torch.save(self.netD.module.state_dict(),
|
||||
os.path.join(self.args.save_dir, f'D{str(self.iteration).zfill(7)}.pt'))
|
||||
torch.save(
|
||||
{'optimG': self.optimG.state_dict(), 'optimD': self.optimD.state_dict()},
|
||||
os.path.join(self.args.save_dir, f'O{str(self.iteration).zfill(7)}.pt'))
|
||||
|
||||
|
||||
def train(self):
|
||||
pbar = range(self.iteration, self.args.iterations)
|
||||
if self.args.global_rank == 0:
|
||||
pbar = tqdm(range(self.args.iterations), initial=self.iteration, dynamic_ncols=True, smoothing=0.01)
|
||||
timer_data, timer_model = timer(), timer()
|
||||
|
||||
for idx in pbar:
|
||||
self.iteration += 1
|
||||
images, masks, filename = next(self.dataloader)
|
||||
images, masks = images.cuda(), masks.cuda()
|
||||
images_masked = (images * (1 - masks).float()) + masks
|
||||
|
||||
if self.args.global_rank == 0:
|
||||
timer_data.hold()
|
||||
timer_model.tic()
|
||||
|
||||
# in: [rgb(3) + edge(1)]
|
||||
pred_img = self.netG(images_masked, masks)
|
||||
comp_img = (1 - masks) * images + masks * pred_img
|
||||
|
||||
# reconstruction losses
|
||||
losses = {}
|
||||
for name, weight in self.args.rec_loss.items():
|
||||
losses[name] = weight * self.rec_loss_func[name](pred_img, images)
|
||||
|
||||
# adversarial loss
|
||||
dis_loss, gen_loss = self.adv_loss(self.netD, comp_img, images, masks)
|
||||
losses[f"advg"] = gen_loss * self.args.adv_weight
|
||||
|
||||
# backforward
|
||||
self.optimG.zero_grad()
|
||||
self.optimD.zero_grad()
|
||||
sum(losses.values()).backward()
|
||||
losses[f"advd"] = dis_loss
|
||||
dis_loss.backward()
|
||||
self.optimG.step()
|
||||
self.optimD.step()
|
||||
|
||||
if self.args.global_rank == 0:
|
||||
timer_model.hold()
|
||||
timer_data.tic()
|
||||
|
||||
# logs
|
||||
scalar_reduced = reduce_loss_dict(losses, self.args.world_size)
|
||||
if self.args.global_rank == 0 and (self.iteration % self.args.print_every == 0):
|
||||
pbar.update(self.args.print_every)
|
||||
description = f'mt:{timer_model.release():.1f}s, dt:{timer_data.release():.1f}s, '
|
||||
for key, val in losses.items():
|
||||
description += f'{key}:{val.item():.3f}, '
|
||||
if self.args.tensorboard:
|
||||
self.writer.add_scalar(key, val.item(), self.iteration)
|
||||
pbar.set_description((description))
|
||||
if self.args.tensorboard:
|
||||
self.writer.add_image('mask', make_grid(masks), self.iteration)
|
||||
self.writer.add_image('orig', make_grid((images+1.0)/2.0), self.iteration)
|
||||
self.writer.add_image('pred', make_grid((pred_img+1.0)/2.0), self.iteration)
|
||||
self.writer.add_image('comp', make_grid((comp_img+1.0)/2.0), self.iteration)
|
||||
|
||||
|
||||
if self.args.global_rank == 0 and (self.iteration % self.args.save_every) == 0:
|
||||
self.save()
|
||||
|
||||
|
||||
@ -0,0 +1,96 @@
|
||||
import argparse
|
||||
|
||||
parser = argparse.ArgumentParser(description='Image Inpainting')
|
||||
|
||||
# data specifications
|
||||
parser.add_argument('--dir_image', type=str, default='../../dataset',
|
||||
help='image dataset directory')
|
||||
parser.add_argument('--dir_mask', type=str, default='../../dataset',
|
||||
help='mask dataset directory')
|
||||
parser.add_argument('--data_train', type=str, default='places2',
|
||||
help='dataname used for training')
|
||||
parser.add_argument('--data_test', type=str, default='places2',
|
||||
help='dataname used for testing')
|
||||
parser.add_argument('--image_size', type=int, default=512,
|
||||
help='image size used during training')
|
||||
parser.add_argument('--mask_type', type=str, default='pconv',
|
||||
help='mask used during training')
|
||||
|
||||
# model specifications
|
||||
parser.add_argument('--model', type=str, default='aotgan',
|
||||
help='model name')
|
||||
parser.add_argument('--block_num', type=int, default=8,
|
||||
help='number of AOT blocks')
|
||||
parser.add_argument('--rates', type=str, default='1+2+4+8',
|
||||
help='dilation rates used in AOT block')
|
||||
parser.add_argument('--gan_type', type=str, default='smgan',
|
||||
help='discriminator types')
|
||||
|
||||
# hardware specifications
|
||||
parser.add_argument('--seed', type=int, default=2021,
|
||||
help='random seed')
|
||||
parser.add_argument('--num_workers', type=int, default=4,
|
||||
help='number of workers used in data loader')
|
||||
|
||||
# optimization specifications
|
||||
parser.add_argument('--lrg', type=float, default=1e-4,
|
||||
help='learning rate for generator')
|
||||
parser.add_argument('--lrd', type=float, default=1e-4,
|
||||
help='learning rate for discriminator')
|
||||
parser.add_argument('--optimizer', default='ADAM',
|
||||
choices=('SGD', 'ADAM', 'RMSprop'),
|
||||
help='optimizer to use (SGD | ADAM | RMSprop)')
|
||||
parser.add_argument('--beta1', type=float, default=0.5,
|
||||
help='beta1 in optimizer')
|
||||
parser.add_argument('--beta2', type=float, default=0.999,
|
||||
help='beta2 in optimier')
|
||||
|
||||
# loss specifications
|
||||
parser.add_argument('--rec_loss', type=str, default='1*L1+250*Style+0.1*Perceptual',
|
||||
help='losses for reconstruction')
|
||||
parser.add_argument('--adv_weight', type=float, default=0.01,
|
||||
help='loss weight for adversarial loss')
|
||||
|
||||
# training specifications
|
||||
parser.add_argument('--iterations', type=int, default=1e6,
|
||||
help='the number of iterations for training')
|
||||
parser.add_argument('--batch_size', type=int, default=8,
|
||||
help='batch size in each mini-batch')
|
||||
parser.add_argument('--port', type=int, default=22334,
|
||||
help='tcp port for distributed training')
|
||||
parser.add_argument('--resume', action='store_true',
|
||||
help='resume from previous iteration')
|
||||
|
||||
|
||||
# log specifications
|
||||
parser.add_argument('--print_every', type=int, default=10,
|
||||
help='frequency for updating progress bar')
|
||||
parser.add_argument('--save_every', type=int, default=1e4,
|
||||
help='frequency for saving models')
|
||||
parser.add_argument('--save_dir', type=str, default='../experiments',
|
||||
help='directory for saving models and logs')
|
||||
parser.add_argument('--tensorboard', action='store_true',
|
||||
help='default: false, since it will slow training. use it for debugging')
|
||||
|
||||
# test and demo specifications
|
||||
parser.add_argument('--pre_train', type=str, default=None,
|
||||
help='path to pretrained models')
|
||||
parser.add_argument('--outputs', type=str, default='../outputs',
|
||||
help='path to save results')
|
||||
parser.add_argument('--thick', type=int, default=15,
|
||||
help='the thick of pen for free-form drawing')
|
||||
parser.add_argument('--painter', default='freeform', choices=('freeform', 'bbox'),
|
||||
help='different painters for demo ')
|
||||
|
||||
|
||||
# ----------------------------------
|
||||
args = parser.parse_args()
|
||||
args.iterations = int(args.iterations)
|
||||
|
||||
args.rates = list(map(int, list(args.rates.split('+'))))
|
||||
|
||||
losses = list(args.rec_loss.split('+'))
|
||||
args.rec_loss = {}
|
||||
for l in losses:
|
||||
weight, name = l.split('*')
|
||||
args.rec_loss[name] = float(weight)
|
||||
@ -0,0 +1,51 @@
|
||||
import cv2
|
||||
import sys
|
||||
|
||||
|
||||
class Sketcher:
|
||||
def __init__(self, windowname, dests, colors_func, thick, type):
|
||||
self.prev_pt = None
|
||||
self.windowname = windowname
|
||||
self.dests = dests
|
||||
self.colors_func = colors_func
|
||||
self.dirty = False
|
||||
self.show()
|
||||
self.thick = thick
|
||||
if type == 'bbox':
|
||||
cv2.setMouseCallback(self.windowname, self.on_bbox)
|
||||
else:
|
||||
cv2.setMouseCallback(self.windowname, self.on_mouse)
|
||||
|
||||
def large_thick(self,):
|
||||
self.thick = min(48, self.thick + 1)
|
||||
|
||||
def small_thick(self,):
|
||||
self.thick = max(3, self.thick - 1)
|
||||
|
||||
def show(self):
|
||||
cv2.imshow(self.windowname, self.dests[0])
|
||||
|
||||
def on_mouse(self, event, x, y, flags, param):
|
||||
pt = (x, y)
|
||||
if event == cv2.EVENT_LBUTTONDOWN:
|
||||
self.prev_pt = pt
|
||||
elif event == cv2.EVENT_LBUTTONUP:
|
||||
self.prev_pt = None
|
||||
|
||||
if self.prev_pt and flags & cv2.EVENT_FLAG_LBUTTON:
|
||||
for dst, color in zip(self.dests, self.colors_func()):
|
||||
cv2.line(dst, self.prev_pt, pt, color, self.thick)
|
||||
self.dirty = True
|
||||
self.prev_pt = pt
|
||||
self.show()
|
||||
|
||||
def on_bbox(self, event, x, y, flags, param):
|
||||
pt = (x, y)
|
||||
if event == cv2.EVENT_LBUTTONDOWN:
|
||||
self.prev_pt = pt
|
||||
elif event == cv2.EVENT_LBUTTONUP:
|
||||
for dst, color in zip(self.dests, self.colors_func()):
|
||||
cv2.rectangle(dst, self.prev_pt, pt, color, -1)
|
||||
self.dirty = True
|
||||
self.prev_pt = None
|
||||
self.show()
|
||||